Kernel 学习笔记
内核常用到的宏:
__read_mostly:
##宏定义在 arch/arm/include/asm/cache.h #define read_mostly __attribute((section(“.data..read_mostly”))) ##实例: bool early_boot_irqs_disabled __read_mostly; ##用来标记 early_boot_irqs_disabled 这个变量经常被读取,如果平台支持缓存,会把这个变量放到cache中__initdata:
##宏定义在include/linux/init.h
#define __initdata __section(.init.data)
#define __initconst __constsection(.init.rodata)
##实例:
char __initdata boot_command_line[COMMAND_LINE_SIZE];
##同上面__read_mostly一样,是用来把这个变量绑定在某个区里面
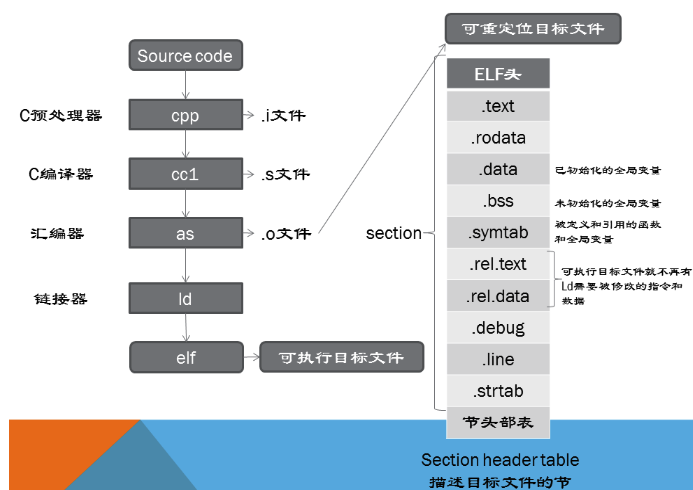
__init、__exit:
#define __init __section(.init.text) __cold notrace
##实例:
static int __init forward_init_module(void)
##用于标记函数,放在.init.text section,标记为初始化的函数,表明该函数供在初始化期间使用。在模块装载之后,模块装载就会将初始化函数扔掉。这样可以将该函数占用的内存释放出来。
#define __exit __section(".exit.text") __exitused __cold notrace
##实例:
static void __exit forward_uninit_module(void)
__cold:
#define __cold __attribute__((__cold__))
##__cold告诉编译器这个函数很可能不被执行到
notrace:
#define notrace __attribute__((no_instrument_function))
##notrace如同GCC的-finstrument-functions() 参数的作用是在程序中加入hook,让它在每次进入和退出函数的时候分别调用这个函数
noinline:
#define noinline __attribute__((noinline))
##阻止该函数被内联
__setup 和 early_param:
unsigned int reset_devices;
EXPORT_SYMBOL(reset_devices);
static int __init set_reset_devices(char *str)
{
reset_devices = 1;
return 1;
}
__setup("reset_devices", set_reset_devices);
##__setup,这个函数就理解为:启动时候如果有接收reset_devices参数,那么就调用set_reset_devices方法
##与__setup相对应的还有一个叫做early_param。这两个宏函数的功能一样,区别就在于early_param定义的参数比__setup更早
源码:
进入源码部分
走完引导阶段,进入内核入口函数start_kernel():(在init/main.c中)
asmlinkage __visible void __init __no_sanitize_address start_kernel(void)
{
- 第一个被调用的函数,用来设置栈溢出标志
- 设置smp即多处理模型,x86_64是空函数
- 初始化调试相关变量
- cgroup 初始化
5 . local_irq_disable(); //禁止中断
early_boot_irqs_disabled = true; //设置中断禁止标志
- 激活第一个CPU用来boot
7 . page_address_init();
该函数初始化高端内存(High Memory)线性地址空间中永久映射相关的全局变量。所以在不支持高端内存即在没有配置CONFIG_HIGHMEM这个宏的时候,该函数是个空函数什么也不做,在ARM系统 中,是没有高端内存相关的代码的,所以这个函数就是个空函数。
在支持高端内存的体系结构中,page_address_init()函数初始化高端内存页表池的链表 struct list_head page_address_pool变量,将内存页地址映射表 struct page_address_map page_address_maps[LIST_PKMAP]中的每一个页地址映射结构 page_address_maps[n]都通过其list成员加入到链表page_address_pool中。初始化内存地址槽结构数组static struct page_address_slot page_address_htable[1«PA_HASH_ORDER(=7)]中的每一个结构变量的链表1h和自旋锁lock,最后初始化高端内存池全局自旋锁pool_lock
- LSM安全模块相关的初始化
- 查找给定机器ID的数据结构信息、配置内存条信息、解析bootloader传递命令行参数,然后根据machine_desc结构体所记录的信息对机器进行一些必要的设置,最后开始正式建立完整的页表
}
一个函数一个函数来,我们先看set_task_stack_end_magic():(在 kernel/fork.c中) 主要用来设置栈溢出标志,方便溢出检查。
#define STACK_END_MAGIC 0x57AC6E9D
void set_task_stack_end_magic(struct task_struct *tsk)
{
unsigned long *stackend;
//获取栈边界地址
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* for overflow detection */
}
其中参数init_task定义在 init/init_task.c中静态初始,是系统中第一个进程:
struct task_struct init_task = {
#ifdef CONFIG_THREAD_INFO_IN_TASK
.thread_info = INIT_THREAD_INFO(init_task),
.stack_refcount = REFCOUNT_INIT(1),
#endif
.............................................................
.stack = init_stack,
..............................................................
};
union thread_union {
#ifndef CONFIG_ARCH_TASK_STRUCT_ON_STACK
struct task_struct task;
#endif
#ifndef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
每个task的内核栈大小THREAD_SIZE,在32位系统是8KB,64位系统里是16KB
x86:
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
因此是8K
x86_64:
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
PAGE_SIZE默认4K,KASAN_STACK_ORDER没有定义时为0,因此是16K; KASAN:动态内存错误检测工具,常用来发现用后释放和越界的bug
ARM:
8k
ARM64:
16K
task_struct、thread_info都用来保存进程相关信息,即进程PCB信息。然而不同的体系结构里,进程需要存储的信息不尽相同,linux使用task_struct存储通用的信息,将体系结构相关的部分存储在thread_info中。这也是为什么struct task_struct在include/linux/sched.h中定义,而thread_info 在arch/ 下体系结构相关头文件里
/* x86 */
struct thread_info {
unsigned long flags; /* low level flags */
u32 status; /* thread synchronous flags */
};
/* ARM */
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
… …
};
smp_setup_processor_id():(在 arch/cpu架构/kernel/setup.c中)
//X86_64
void __init __weak smp_setup_processor_id(void)
{
}
//ARM64
void __init smp_setup_processor_id(void)
{
//获取CPU ID
u64 mpidr = read_cpuid_mpidr() & MPIDR_HWID_BITMASK;
set_cpu_logical_map(0, mpidr);
/*
* clear __my_cpu_offset on boot CPU to avoid hang caused by
* using percpu variable early, for example, lockdep will
* access percpu variable inside lock_release
*/
set_my_cpu_offset(0);
pr_info("Booting Linux on physical CPU 0x%010lx [0x%08x]\n",(unsigned long)mpidr, read_cpuid_id());
}
//ARM32
void __init smp_setup_processor_id(void)
{
int i;
//判断是否是smp系统,如果是则从arm协处理器读取当前cpuid,否则为0
u32 mpidr = is_smp() ? read_cpuid_mpidr() & MPIDR_HWID_BITMASK : 0;
//根据level确定cpu号,即cpu=(mpidr>>0)&0xff
u32 cpu = MPIDR_AFFINITY_LEVEL(mpidr, 0);
cpu_logical_map(0) = cpu;
for (i = 1; i < nr_cpu_ids; ++i)
cpu_logical_map(i) = i == cpu ? 0 : i;
/*
* clear __my_cpu_offset on boot CPU to avoid hang caused by
* using percpu variable early, for example, lockdep will
* access percpu variable inside lock_release
*/
set_my_cpu_offset(0);
pr_info("Booting Linux on physical CPU 0x%x\n", mpidr);
}
debug_objects_early_init():(在 lib/debugobjects.c中) ,主要用来初始化obj_hash,obj_static_pool两个全局变量
/*
* Called during early boot to initialize the hash buckets and link
* the static object pool objects into the poll list. After this call
* the object tracker is fully operational.
*/
void __init debug_objects_early_init(void)
{
int i;
for (i = 0; i < ODEBUG_HASH_SIZE; i++)
raw_spin_lock_init(&obj_hash[i].lock);
for (i = 0; i < ODEBUG_POOL_SIZE; i++)
hlist_add_head(&obj_static_pool[i].node, &obj_pool);
}
cgroup_init_early():(在 kernel/cgroup.c中) ,
什么是CGROUP:
cgroups是Linux下控制一个(或一组)进程的资源限制机制,全称是control groups;
可以对cpu、内存等资源做精细化控制,比如目前很多的Docker在Linux下就是基于cgroups提供的资源限制机制来实现资源控制的.
在cgroup出现之前,只能对一个进程做资源限制,比如通过sched_setaffinity设置进程cpu亲和性,使用ulimit限制进程打开文件上限、栈大小等。
从实现角度来看,cgroups实现了一个通用的进程分组框架,不同资源的具体管理工作由各cgroup子系统来实现,
当需要多个限制策略比如同时针对cpu和内存进行限制,则同时关联多个cgroup子系统即可.
cgroups子系统
cgroups为每种资源定义了一个子系统,典型的子系统如下:
cpu 子系统,主要限制进程的 cpu 使用率。
cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
memory 子系统,可以限制进程的 memory 使用量。
blkio 子系统,可以限制进程的块设备 io。
devices 子系统,可以控制进程能够访问某些设备。
net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
每个子系统都是定义了一套限制策略,它们需要与内核的其他模块配合来完成资源限制功能,比如对 cpu 资源的限制是通过进程调度模块根据 cpu 子系统的配置来完成的;
对内存资源的限制则是内存模块根据 memory 子系统的配置来完成的,而对网络数据包的控制则需要 Traffic Control 子系统来配合完成。
cgroups原理:
Linux 下管理进程的数据结构是 task_struct,其中与cgrups相关属性如下:
struct task_struct {
.......
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock: */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock: */
struct list_head cg_list;
#endif
......
}
cgroups 指针指向了一个 css_set 结构,而css_set 存储了与进程有关的 cgroups 信息。
cg_list 是一个嵌入的 list_head 结构,用于将连到同一个 css_set 的进程组织成一个链表 <mark>struct css\_set :</mark>
struct css_set {
/*
* Set of subsystem states, one for each subsystem. This array is
* immutable after creation apart from the init_css_set during
* subsystem registration (at boot time).
* 存储一组指向 cgroup_subsys_state 的指针。一个cgroup_subsys_state 就是进程与一个特定子系统相关的信息。
* 通过这个指针数组,进程就可以获得相应的 cgroups 控制信息
*/
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
/* reference count css_set 的引用数,因为一个 css_set 可以被多个进程公用,只要这些进程的 cgroups 信息相同 */
refcount_t refcount;
/*
* For a domain cgroup, the following points to self. If threaded,
* to the matching cset of the nearest domain ancestor. The
* dom_cset provides access to the domain cgroup and its csses to
* which domain level resource consumptions should be charged.
*/
struct css_set *dom_cset;
/* the default cgroup associated with this css_set */
struct cgroup *dfl_cgrp;
/* internal task count, protected by css_set_lock */
int nr_tasks;
/*
* Lists running through all tasks using this cgroup group.
* mg_tasks lists tasks which belong to this cset but are in the
* process of being migrated out or in. Protected by
* css_set_rwsem, but, during migration, once tasks are moved to
* mg_tasks, it can be read safely while holding cgroup_mutex.
*/
struct list_head tasks;
struct list_head mg_tasks;
struct list_head dying_tasks;
/* all css_task_iters currently walking this cset */
struct list_head task_iters;
/*
* On the default hierarhcy, ->subsys[ssid] may point to a css
* attached to an ancestor instead of the cgroup this css_set is
* associated with. The following node is anchored at
* ->subsys[ssid]->cgroup->e_csets[ssid] and provides a way to
* iterate through all css's attached to a given cgroup.
*/
struct list_head e_cset_node[CGROUP_SUBSYS_COUNT];
/* all threaded csets whose ->dom_cset points to this cset */
struct list_head threaded_csets;
struct list_head threaded_csets_node;
/*
* List running through all cgroup groups in the same hash
* slot. Protected by css_set_lock
* 用于把所有 css_set 组织成一个 hash 表,这样内核可以快速查找特定的 css_set
*/
struct hlist_node hlist;
/*
* List of cgrp_cset_links pointing at cgroups referenced from this
* css_set. Protected by css_set_lock.
*/
struct list_head cgrp_links;
....
};
struct cgroup\_subsys\_state :
struct cgroup_subsys_state {
/* PI: the cgroup that this css is attached to */
struct cgroup *cgroup;
/* PI: the cgroup subsystem that this css is attached to */
struct cgroup_subsys *ss;
/* reference count - access via css_[try]get() and css_put() */
struct percpu_ref refcnt;
/* siblings list anchored at the parent's ->children */
struct list_head sibling;
struct list_head children;
/* flush target list anchored at cgrp->rstat_css_list */
struct list_head rstat_css_node;
/*
* PI: Subsys-unique ID. 0 is unused and root is always 1. The
* matching css can be looked up using css_from_id().
*/
int id;
unsigned int flags;
/*
* Monotonically increasing unique serial number which defines a
* uniform order among all csses. It's guaranteed that all
* ->children lists are in the ascending order of ->serial_nr and
* used to allow interrupting and resuming iterations.
*/
u64 serial_nr;
/*
* Incremented by online self and children. Used to guarantee that
* parents are not offlined before their children.
*/
atomic_t online_cnt;
/*
* PI: the parent css. Placed here for cache proximity to following
* fields of the containing structure.
*/
struct cgroup_subsys_state *parent;
};
有时间在详细解读cgroup,先看一下cgroup_init_early():
int __init cgroup_init_early(void)
{
static struct cgroup_fs_context __initdata ctx;
struct cgroup_subsys *ss;
int i;
//初始化根cgroup
ctx.root = &cgrp_dfl_root;
init_cgroup_root(&ctx);
cgrp_dfl_root.cgrp.self.flags |= CSS_NO_REF;
//初始化css_set
RCU_INIT_POINTER(init_task.cgroups, &init_css_set);
//循环遍历所有子系统
for_each_subsys(ss, i) {
WARN(!ss->css_alloc || !ss->css_free || ss->name || ss->id,
"invalid cgroup_subsys %d:%s css_alloc=%p css_free=%p id:name=%d:%s\n",
i, cgroup_subsys_name[i], ss->css_alloc, ss->css_free,
ss->id, ss->name);
WARN(strlen(cgroup_subsys_name[i]) > MAX_CGROUP_TYPE_NAMELEN,
"cgroup_subsys_name %s too long\n", cgroup_subsys_name[i]);
ss->id = i;
ss->name = cgroup_subsys_name[i];
if (!ss->legacy_name)
ss->legacy_name = cgroup_subsys_name[i];
//该子系统是否需要初始化
if (ss->early_init)
cgroup_init_subsys(ss, true);
}
return 0;
}
数组 cgroup\_subsys\_name []定义:
static const char *cgroup\_subsys\_name[] = {#include \<linux/cgroup\_subsys.h\>};
#if IS_ENABLED(CONFIG_CPUSETS)
SUBSYS(cpuset)
#endif
#if IS_ENABLED(CONFIG_CGROUP_SCHED)
SUBSYS(cpu)
#endif
#if IS_ENABLED(CONFIG_CGROUP_CPUACCT)
SUBSYS(cpuacct)
#endif
#if IS_ENABLED(CONFIG_BLK_CGROUP)
SUBSYS(io)
#endif
#if IS_ENABLED(CONFIG_MEMCG)
SUBSYS(memory)
#endif
#if IS_ENABLED(CONFIG_CGROUP_DEVICE)
SUBSYS(devices)
#endif
#if IS_ENABLED(CONFIG_CGROUP_FREEZER)
SUBSYS(freezer)
#endif
#if IS_ENABLED(CONFIG_CGROUP_NET_CLASSID)
SUBSYS(net_cls)
#endif
#if IS_ENABLED(CONFIG_CGROUP_PERF)
SUBSYS(perf_event)
#endif
#if IS_ENABLED(CONFIG_CGROUP_NET_PRIO)
SUBSYS(net_prio)
#endif
#if IS_ENABLED(CONFIG_CGROUP_HUGETLB)
SUBSYS(hugetlb)
#endif
#if IS_ENABLED(CONFIG_CGROUP_PIDS)
SUBSYS(pids)
#endif
#if IS_ENABLED(CONFIG_CGROUP_RDMA)
SUBSYS(rdma)
#endif
/*
* The following subsystems are not supported on the default hierarchy.
*/
#if IS_ENABLED(CONFIG_CGROUP_DEBUG)
SUBSYS(debug)
#endif
boot_cpu_init():(在 kernel/cpu.c中) ,
/*
* Activate the first processor.
*/
void __init boot_cpu_init(void)
{
//获取cpu id
int cpu = smp_processor_id();
/* Mark the boot cpu "present", "online" etc for SMP and UP case */
//根据cpu id设置在线、激活 、present、possible
set_cpu_online(cpu, true);
set_cpu_active(cpu, true);
set_cpu_present(cpu, true);
set_cpu_possible(cpu, true);
#ifdef CONFIG_SMP
__boot_cpu_id = cpu;
#endif
}
early_security_init():(在 security/security.c中) ,LSM中文全称是linux安全模块。英文全称:linux security module. LSM是一种轻量级、通用的访问控制框架,适合多种访问控制模型以内核模块的形式实现.
LSM的架构图如下:
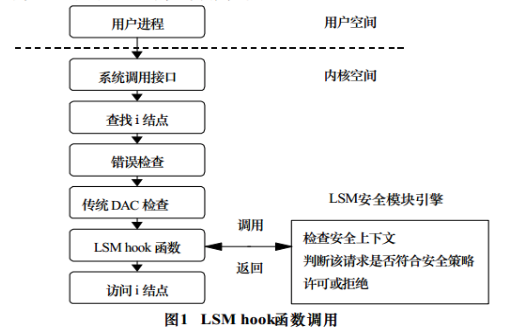
int __init early_security_init(void)
{
int i;
//初始化安全 lsm hook hlist_head;
struct hlist_head *list = (struct hlist_head *) &security_hook_heads;
struct lsm_info *lsm;
for (i = 0; i < sizeof(security_hook_heads) / sizeof(struct hlist_head);
i++)
INIT_HLIST_HEAD(&list[i]);
//根据__start_early_lsm_info 、__end_early_lsm_info列表,初始化lsm,x86_64:__end_early_lsm_info-__start_early_lsm_info=0
for (lsm = __start_early_lsm_info; lsm < __end_early_lsm_info; lsm++) {
if (!lsm->enabled)
lsm->enabled = &lsm_enabled_true;
prepare_lsm(lsm);
initialize_lsm(lsm);
}
return 0;
}
setup_arch(char **cmdline_p);:(在 arch/x86/kernel/setup.c中)
void __init setup_arch(char **cmdline_p)
{
//保留_text 到 __end_of_kernel_reserve 之间内核占用的内存
memblock_reserve(__pa_symbol(_text),
(unsigned long)__end_of_kernel_reserve - (unsigned long)_text);
//保留 page 0
memblock_reserve(0, PAGE_SIZE);
//保留 ramdisk 内存,如果有的话
early_reserve_initrd();
//这个不是很了解,感觉像是保留和显示相关的内存
olpc_ofw_detect();
//初始化中断描述表b
idt_setup_early_traps();
//根据cpu_dev_register()注册的设备,填充cpu_devs[],并填充boot_cpu_data结构信息
early_cpu_init();
//没太懂,初始化一个空操作指令数组,类似于延时?!占位?用于hook?
arch_init_ideal_nops();
//处理静态定义的jump label,执行跳转指令或是nop指令
jump_label_init();
//加载静态定义的跳转表,注册模块通知
static_call_init();
//函数用于初始化slot_virt[8] 数组,该数据用于管理2M虚拟地址空间,每个slot用于管理64 pages,每个page大小4K,并把这2M空间映射成PMD,再把PMD加入PTE表。
early_ioremap_init();
//把olpc加入pgd表
setup_olpc_ofw_pgd();
....
//
init_cache_modes();
//KASLR是kernel address space layout randomization的缩写,直译过来就是内核地址空间布局随机化。
//KASLR技术允许kernel image加载到VMALLOC区域的任何位置。当KASLR关闭的时候,kernel image都会映射到一个固定的链接地址.相对安全
kernel_randomize_memory();
}